Архитектура¶
StarRocks имеет простую архитектуру. Вся система состоит только из двух типов компонентов: frontend-узлы и backend-узлы. Узлы frontend называются FE. Существует два типа узлов backend: BE и CN (Compute Nodes). BE разворачиваются при использовании локального хранилища данных, а CN — когда данные хранятся в object storage или HDFS. StarRocks не полагается на внешние компоненты, что упрощает развёртывание и обслуживание. Узлы можно горизонтально масштабировать без простоя сервиса. Кроме того, StarRocks применяет механизм репликации для метаданных и сервисных данных, повышая надёжность и предотвращая single point of failure (SPOF).
StarRocks совместима с протоколами MySQL и поддерживает стандартный язык SQL. Пользователи могут легко подключаться к StarRocks из клиентов MySQL, чтобы быстро получать аналитику.
Архитектурные варианты¶
StarRocks поддерживает архитектуры shared-nothing (каждый BE хранит часть данных на локальном диске) и shared-data (все данные хранятся в object storage или HDFS, а каждый CN имеет только cache на локальном диске). Место хранения данных можно выбирать.

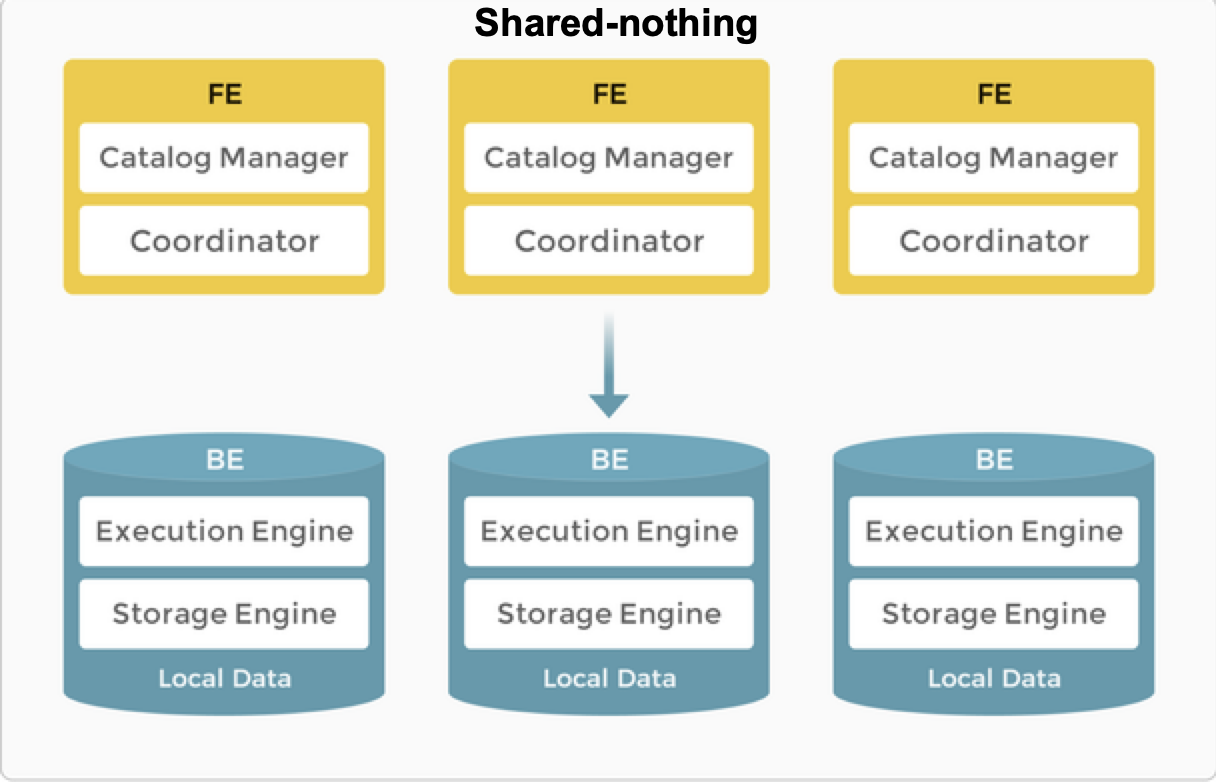
Локальное хранение данных (Shared-nothing)¶
Локальное хранилище обеспечивает улучшенную задержку запросов для real-time сценариев.
Как типичная MPP СУБД, StarRocks поддерживает архитектуру shared-nothing. В этой архитектуре BE отвечают и за хранение, и за вычисления. Прямой доступ к локальным данным на BE позволяет выполнять вычисления локально, избегая передачи и копирования данных, что обеспечивает сверхбыструю обработку запросов и аналитики. Архитектура поддерживает мультирепликационное хранение данных, повышая способность к высокой конкуррентности запросов и обеспечивая надёжность хранения данных. Она хорошо подходит для сценариев, где важна максимальная производительность запросов.
Узлы¶
В архитектуре shared-nothing StarRocks состоит из двух типов узлов: FE и BE (см. описание выше).
Узлы FE отвечают за управление метаданными и построение планов выполнения.
Узлы BE исполняют планы запросов и хранят данные. При этом используется локальное хранилище для ускорения запросов и механизм многократных реплик для высокой доступности данных.
Узлы типа FE¶
Узлы FE отвечают за управление метаданными, управление клиентскими соединениями, планирование запросов и их диспетчеризацию. Каждый FE-узел использует механизм хранения данных BDB JE (Berkeley DB Java Edition) для хранения и поддержания полной копии метаданных в памяти, обеспечивая консистентные сервисы на всех FE-узлах. FE могут работать как leader, follower и observer. При сбое leader‑узла среди follower-узлов проводится новое избрание лидера по протоколу Raft.
Роль FE |
Управление метаданными |
Избрание лидера |
|---|---|---|
Leader |
Leader FE читает и пишет метаданные. Follower и observer FE могут только читать метаданные. Они проксируют запросы на запись метаданных в leader FE. Leader FE обновляет метаданные и с помощью протокола Raft синхронизирует изменения метаданных на follower и observer FE. Запись данных считается успешной только после синхронизации изменений метаданных с более чем половиной follower FE. |
Технически leader FE также является узлом типа follower и избирается из числа follower FE. Для избрания лидера необходимо, чтобы более половины follower FE в кластере были активны. При отказе leader FE follower-узлы инициируют новый раунд выборов лидера. |
Follower |
Follower могут только читать метаданные. Они синхронизируют и проигрывают журналы с leader FE для обновления метаданных. |
Follower участвуют в выборах лидера; требуется, чтобы более половины follower в кластере были активны. |
Observer |
Observer синхронизируют и проигрывают журналы с leader FE для обновления метаданных. |
Observer в основном используются для увеличения конкуррентности запросов в кластере. Observer не участвуют в выборах лидера и поэтому не создают дополнительной нагрузки на процесс выборов. |
Узлы типа BE¶
Узлы типа BE отвечают за хранение данных и исполнение SQL-запросов.
Хранение данных: все узлы BE равноправны по возможностям хранения. Узлы FE распределяют данные по BE согласно предопределённым правилам. BE преобразуют загружаемые данные, записывают их в требуемом формате и создают индексы.
Исполнение SQL: FE парсят каждый SQL‑запрос в логический план согласно семантике запроса, затем преобразуют его в физические планы выполнения, исполняемые на BE. BE, на которых находятся целевые данные, исполняют запрос. Это устраняет необходимость передачи и копирования данных, обеспечивая высокую производительность запросов.
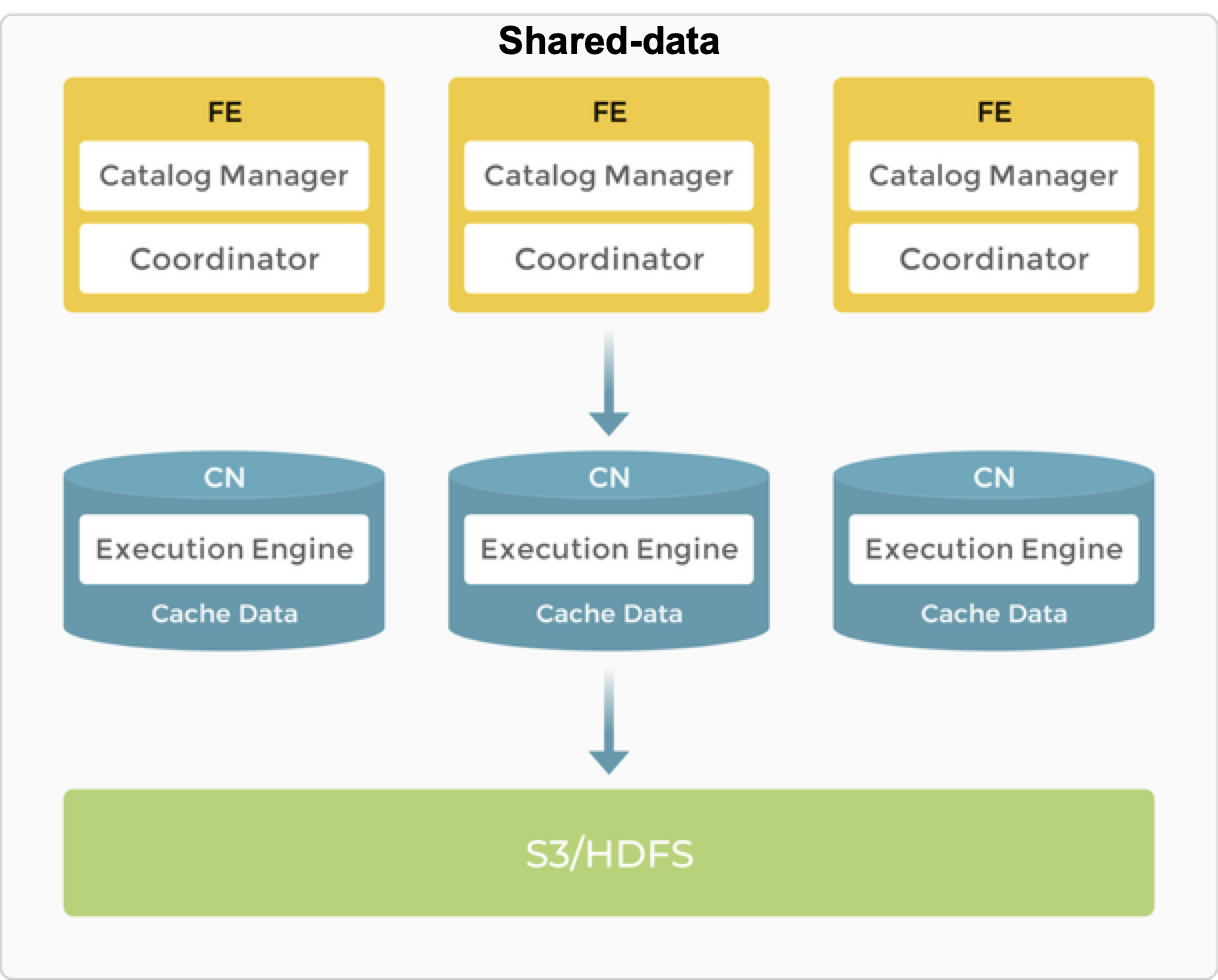
Удаленное хранение данных (Shared-data)¶
Object storage и HDFS обеспечивают преимущества по стоимости, надёжности и масштабируемости. Кроме масштабирования хранилища, узлы CN можно добавлять и удалять без ребалансировки данных, поскольку хранение и вычисления разделены.
В архитектуре shared-data BE заменяются на «compute nodes (CN)», которые отвечают только за вычисления и кэширование «горячих» данных. Данные хранятся в недорогих и надёжных удалённых системах хранения, таких как Amazon S3, Google Cloud Storage, Azure Blob Storage, MinIO и т. п. При попадании в кэш производительность запросов сопоставима с архитектурой shared-nothing. Узлы CN можно добавлять или удалять по требованию за секунды. Такая архитектура снижает стоимость хранения, обеспечивает лучшую изоляцию ресурсов, высокую эластичность и масштабируемость.
Архитектура shared-data остаётся столь же простой, как и shared-nothing. Она также включает только два типа узлов: FE и CN. Единственное отличие — требуется предоставить backend object storage.
Узлы¶
FE в архитектуре shared-data выполняют те же функции, что и в shared-nothing.
BE заменены на CN (Compute Nodes), а функция хранения вынесена в object storage или HDFS. CN — stateless вычислительные узлы, выполняющие все функции BE, кроме хранения данных.
Хранилище¶
Кластеры StarRocks в режиме shared-data поддерживают два решения для хранения: object storage (например, AWS S3, Google GCS, Azure Blob Storage, MinIO) и HDFS.
В shared-data кластере формат файлов данных совпадает с форматом в shared-nothing (с совмещёнными хранением и вычислениями). Данные организованы в segment‑файлы, а различные технологии индексирования переиспользуются в cloud‑native таблицах, предназначенных для shared-data кластеров.
Кэш¶
Shared-data кластеры StarRocks разделяют хранение и вычисления, позволяя масштабировать их независимо, что снижает издержки и повышает эластичность. Однако это может влиять на производительность запросов.
Чтобы минимизировать влияние, StarRocks реализует многоуровневую систему доступа к данным, включающую память, локальный диск и удалённое хранилище, чтобы лучше соответствовать различным потребностям бизнеса.
Запросы к «горячим» данным сканируют кэш и затем локальный диск; «холодные» данные должны быть загружены из object storage в локальный кэш для ускорения последующих запросов. Держа «горячие» данные близко к вычислительным узлам, StarRocks достигает действительно высокой производительности вычислений при экономичном хранении. Доступ к «холодным» данным оптимизирован стратегиями предвыборки (prefetch), эффективно устраняя ограничители производительности запросов.
Кэширование можно включить при создании таблиц. Если кэширование включено, данные будут записываться как на локальный диск, так и в backend object storage. Во время выполнения запросов узлы CN сначала читают данные с локального диска. Если данные не найдены, они извлекаются из backend object storage и одновременно кешируются на локальный диск.