Обзор таблиц¶
Таблицы являются единицами хранения данных. Понимание структуры таблиц в StarRocks и грамотное проектирование схемы позволяют оптимизировать организацию данных и повысить эффективность запросов. Кроме того, по сравнению с традиционными СУБД, StarRocks поддерживает колоночное хранение сложных полуструктурированных данных, таких как JSON и ARRAY, что улучшает производительность запросов.
В этом разделе структура таблиц в StarRocks рассматривается как с базовой, так и с общей точки зрения.
Начиная с версии v3.3.1, StarRocks поддерживает создание временных таблиц в Default Catalog.
Быстрый старт по базовой структуре таблицы¶
Как и в других реляционных базах данных, таблица логически состоит из строк и столбцов:
Строки: каждая строка содержит запись. В строке хранится набор взаимосвязанных значений данных.
Столбцы: столбцы определяют атрибуты каждой записи. Каждый столбец хранит данные конкретного атрибута. Например, таблица сотрудников может включать столбцы name, employee ID, department и salary; каждый столбец хранит соответствующие данные. Данные в каждом столбце имеют одинаковый тип данных. Все строки в таблице содержат одинаковое количество столбцов.
Создание таблицы в StarRocks достаточно просто. Нужно определить столбцы и их типы данных в операторе CREATE TABLE. Пример:
CREATE DATABASE example_db;
USE example_db;
CREATE TABLE user_access (
uid int,
name varchar(64),
age int,
phone varchar(16),
last_access datetime,
credits double
)
ORDER BY (uid, name);
Приведённый выше пример CREATE TABLE создаёт таблицу типа Duplicate Key. Для столбцов такой таблицы не накладываются ограничения, поэтому в ней могут присутствовать дублирующиеся строки. Первые два столбца Duplicate Key‑таблицы указываются как сортировочные для формирования sort key. Данные хранятся в отсортированном по sort key виде, что ускоряет индексацию при выполнении запросов.
Начиная с версии v3.3.0, таблицы Duplicate Key поддерживают указание sort key с помощью оператора ORDER BY. Если заданы одновременно ORDER BY и DUPLICATE KEY, то DUPLICATE KEY не применяется.
Выполните операцию DESCRIBE, чтобы просмотреть схему таблицы.
MySQL [test]> DESCRIBE user_access;
+-------------+-------------+------+-------+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------------+-------------+------+-------+---------+-------+
| uid | int | YES | true | NULL | |
| name | varchar(64) | YES | true | NULL | |
| age | int | YES | false | NULL | |
| phone | varchar(16) | YES | false | NULL | |
| last_access | datetime | YES | false | NULL | |
| credits | double | YES | false | NULL | |
+-------------+-------------+------+-------+---------+-------+
6 rows in set (0.00 sec)
Выполните операцию SHOW CREATE TABLE, чтобы увидеть оператор CREATE TABLE.
MySQL [example_db]> SHOW CREATE TABLE user_access\G
*************************** 1. row ***************************
Table: user_access
Create Table: CREATE TABLE `user_access` (
`uid` int(11) NULL COMMENT "",
`name` varchar(64) NULL COMMENT "",
`age` int(11) NULL COMMENT "",
`phone` varchar(16) NULL COMMENT "",
`last_access` datetime NULL COMMENT "",
`credits` double NULL COMMENT ""
) ENGINE=OLAP
DUPLICATE KEY(`uid`, `name`)
DISTRIBUTED BY RANDOM
ORDER BY(`uid`, `name`)
PROPERTIES (
"bucket_size" = "4294967296",
"compression" = "LZ4",
"fast_schema_evolution" = "true",
"replicated_storage" = "true",
"replication_num" = "3"
);
1 row in set (0.01 sec)
Понимание расширенной структуры таблицы¶
Глубокое понимание структур таблиц StarRocks поможет спроектировать эффективную систему управления данными, адаптированную под ваши бизнес‑задачи.
Типы таблиц¶
StarRocks предоставляет четыре типа таблиц: Duplicate Key, Primary Key, Aggregate и Unique Key, чтобы хранить данные для различных сценариев — сырые данные, часто обновляемые данные в реальном времени и агрегированные данные.
Duplicate Key— простые и удобные таблицы. Для столбцов не задаются ограничения, поэтому возможны дубликаты строк. Подходят для хранения сырых данных, например логов, которым не требуются ограничения или предагрегация.Primary Key— мощные таблицы. Для столбцов с первичным ключом действуют ограничения на уникальность иNOT NULL. Поддерживаются частые обновления в реальном времени и частичные обновления столбцов при высокой производительности запросов — подходят для сценариев real‑time запросов.Aggregate— таблицы для хранения предагрегированных данных, что уменьшает объём сканируемых и вычисляемых данных и ускоряет агрегирующие запросы.Unique— также подходят для часто обновляемых данных реального времени, но постепенно заменяются таблицамиPrimary Keyкак более мощным типом.
Распределение данных¶
StarRocks использует двухуровневую стратегию распределения данных: партиционирование + бакетирование, чтобы равномерно распределять данные по узлам BE. Грамотное проектирование распределения позволяет эффективно снизить объём сканируемых данных и максимизировать параллелизм, тем самым повышая производительность запросов.
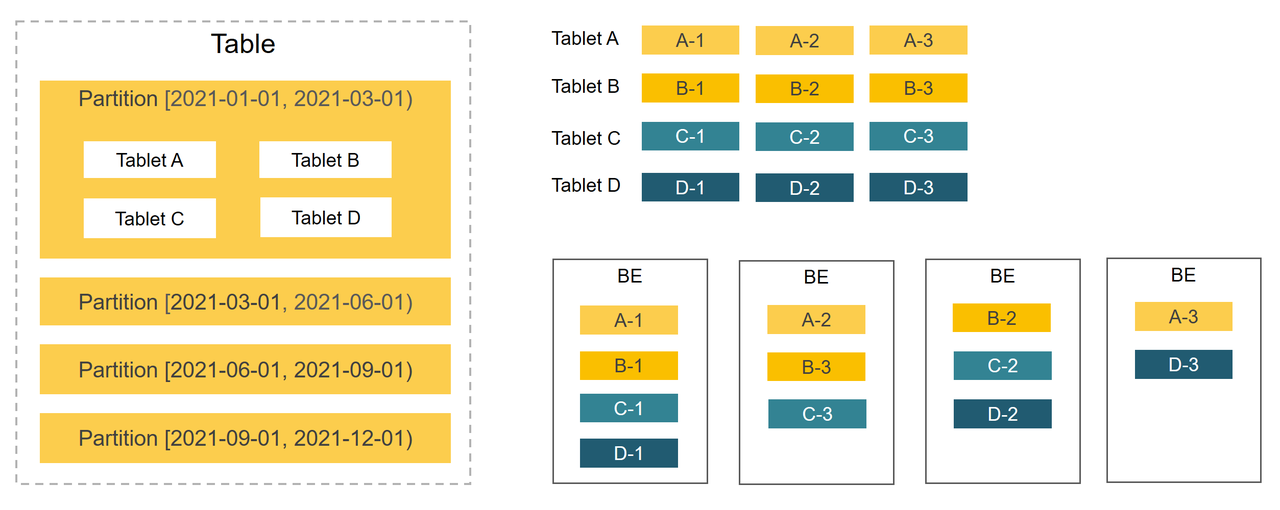
Партиционирование¶
Первый уровень — партиционирование: данные в таблицах можно делить на более мелкие единицы управления на основе столбцов партиционирования, обычно это дата/время. При выполнении запросов отсечение партиций (partition pruning) уменьшает объём сканируемых данных и повышает производительность.
StarRocks предоставляет удобный метод — expression partitioning, а также более гибкие — range и list partitioning.
Бакетирование¶
Второй уровень — бакетирование: данные внутри партиции дополнительно делятся на меньшие единицы управления. Реплики каждого бакета равномерно распределяются по BE-узлам для высокой доступности.
StarRocks поддерживает два метода бакетирования:
Hash bucketing: распределение по бакетам на основе хеш‑значений бакет‑ключа. Рекомендуется выбирать столбцы, часто используемые в условиях фильтрации, что ускоряет запросы.Random bucketing: случайное распределение данных по бакетам. Более простой и удобный способ.
Типы данных¶
Помимо базовых типов данных, таких как NUMERIC, DATE и STRING, StarRocks поддерживает полуструктурированные типы ARRAY, JSON, MAP и STRUCT.
Индексы¶
Индекс — это специальная структура данных, указывающая на данные в таблице. Когда в запросах в условиях используются индексируемые столбцы, StarRocks быстро находит соответствующие данные.
StarRocks предоставляет встроенные индексы: Prefix, Ordinal и ZoneMap. Также пользователи могут создавать Bitmap и Bloom Filter индексы для дополнительного ускорения.
Ограничения¶
Ограничения обеспечивают целостность, согласованность и корректность данных. Столбцы первичного ключа в таблицах Primary Key должны иметь уникальные значения и только NOT NULL значения. Столбцы aggregate key в таблицах Aggregate и unique key в таблицах Unique должны быть уникальны.
Временная таблица¶
При обработке данных может понадобиться сохранять промежуточные результаты для повторного использования. В ранних версиях StarRocks поддерживался только CTE (Common Table Expressions) для определения временных результатов в рамках одного запроса. Однако CTE — это логическая конструкция: результаты не сохраняются физически и не могут использоваться между разными запросами, что накладывает ограничения. Если же создавать обычные таблицы для хранения промежуточных результатов, придётся управлять их жизненным циклом, что затратно.
Чтобы решить эту проблему, в версии v3.3.1 появились временные таблицы. Они позволяют временно сохранять данные (например, промежуточные результаты ETL) в таблице; их жизненный цикл привязан к сессии и управляется StarRocks. При завершении сессии временные таблицы автоматически очищаются. Временные таблицы видимы только в текущей сессии; разные сессии могут создавать временные таблицы с одинаковыми именами.
Использование¶
Вы можете использовать ключевое слово TEMPORARY в следующих SQL‑операторах для создания и удаления временных таблиц:
CREATE TABLECREATE TABLE AS SELECTCREATE TABLE LIKEDROP TABLE
Как и другие нативные таблицы, временные таблицы необходимо создавать в базе данных Default Catalog. Однако из‑за их сессионной природы к ним не применяются требования уникальности имён. Вы можете создавать временные таблицы с одинаковыми именами в разных сессиях или даже с теми же именами, что и у нативных (не временных) таблиц.
Если в базе существуют временная и нативная таблицы с одинаковым именем, приоритет у временной. В пределах сессии все операции с таким именем затрагивают только временную таблицу.
Ограничения для временных таблиц¶
Хотя использование похоже на нативные таблицы, есть отличия и ограничения:
Временные таблицы создаются только в
Default Catalog.Настройка
colocate groupне поддерживается. Явно заданное свойствоcolocate_withбудет проигнорировано.При создании необходимо указывать
ENGINEкакolap.Операторы
ALTER TABLEне поддерживаются.Нельзя создавать представления и материализованные представления по временным таблицам.
Операции
EXPORTне поддерживаются.Нельзя создавать временные таблицы или загружать в них данные асинхронными задачами через
SUBMIT TASK.
Дополнительные возможности¶
Помимо перечисленного, вы можете задействовать и другие функции для построения более надёжной схемы таблиц: использовать столбцы Bitmap и HLL для ускорения distinct‑подсчётов, задавать generated‑столбцы или автоинкрементные столбцы для ускорения некоторых запросов, настраивать гибкое и автоматическое охлаждение хранения для снижения затрат на обслуживание, а также использовать Colocate Join для ускорения многотабличных JOIN‑запросов. Подробнее см. описание работы оператора CREATE TABLE.